
“서버 성능을 올려야겠는데…”

위 얘기를 들으면 뭐부터 생각나시나요?
- 인스턴스의 티어를 올려요! (Scale-Up)
- 서버를 늘려요! (Scale-out)
- 캐싱을 적용해요 등등..
다양한 방법이 있습니다. 자 그럼 단순하게 Scale-Up, Scale-Out으로 서버의 성능이 쭉쭉 늘까요? 돈이 드는 만큼 한 번 확인해 봅시다.
1. 단순 EC2 Scale Up
기대 값
| 인스턴스 이름 | 온디맨드 시간당 요금 | vCPU | 메모리 | 스토리지 | 네트워크 성능 |
|---|---|---|---|---|---|
| t3.small | 0.0208 USD | 2 | 2GiB | EBS 전용 | 최대 5기가비트 |
| t3.medium | 0.0416 USD | 2 | 4GiB | EBS 전용 | 최대 5기가비트 |
| t3.large | 0.0832 USD | 2 | 8GiB | EBS 전용 | 최대 5기가비트 |
| t3.xlarge | 0.1664 USD | 4 | 16GiB | EBS 전용 | 최대 5기가비트 |
| t3.2xlarge | 0.3328 USD | 8 | 32GiB | EBS 전용 | 최대 5기가비트 |
위의 표는 AWS EC2 서울 리전의 가격과 스펙을 나열한 표입니다.
AWS에서 단순히 인스턴스의 성능만 올려봅시다. 가격이 2배씩 증가하니까 성능도 2배씩 올랐으면 좋겠네요!
실제 값
- DB Only : JPA를 활용해 DB 조회를 수행하며, 대부분 DB I/O 작업으로 이루어져 있는 API.
- CPU Only : 복잡한 연산 로직 수행하며, 대부분 CPU 작업으로 이루어져 있는 API.
- ALL : 위의 두 작업을 같이 수행하는 API.
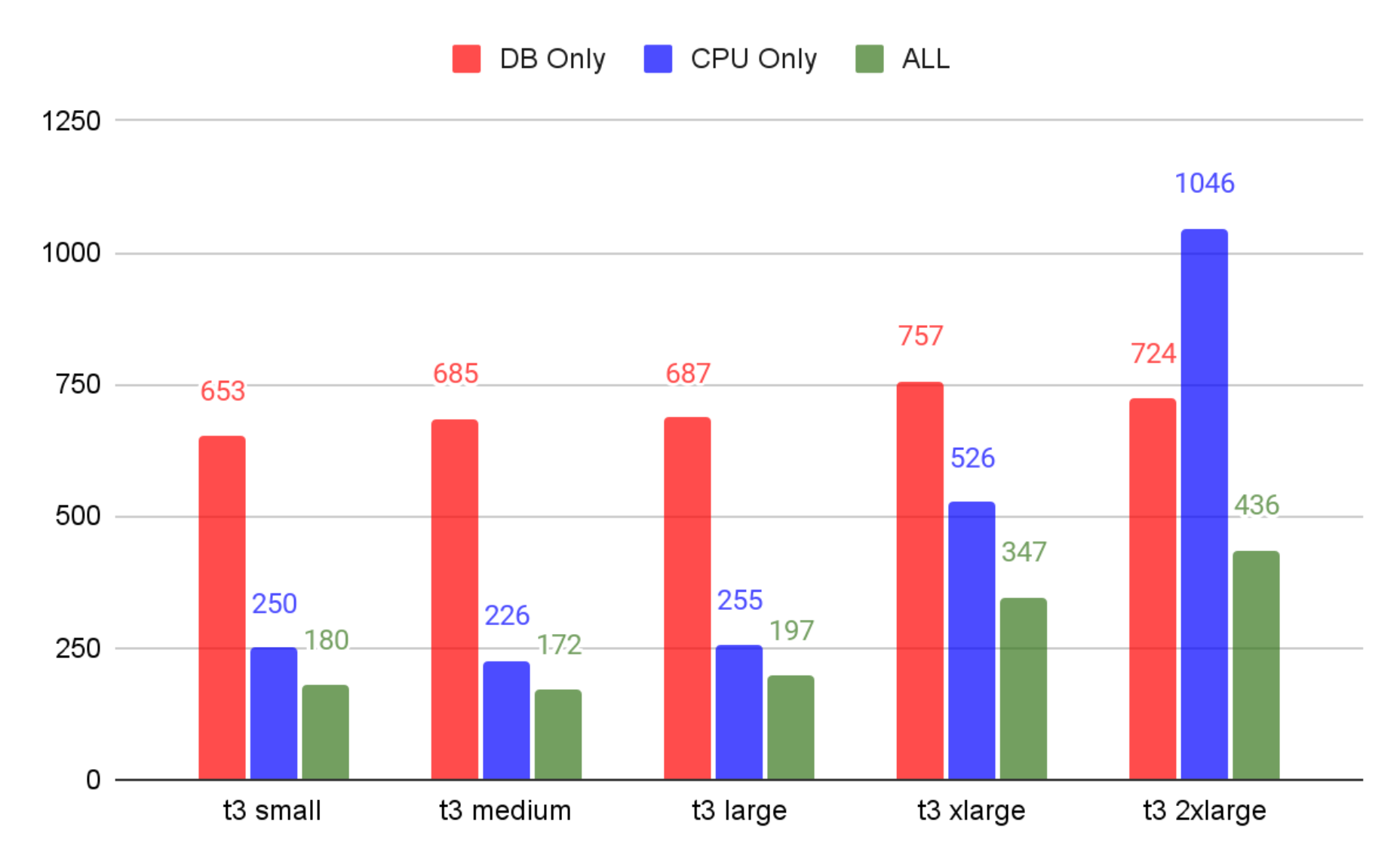
인스턴스의 티어를 올리면서 측정한 TPS입니다. 아래와 같이 분석할 수 있습니다.
- 가격은 2배씩 증가하지만 성능은 가격만큼 오르지 않는다. (오차 범위 이내)
- CPU 코어수에 따라 Cpu와 관련된 작업(Cpu Only, ALL)이 오르는 것을 볼 수 있다.
2. 단순 RDS Scale-Up
기대 값
| 인스턴스 이름 (MySql) | 시간당 요금 | 코어 개수 | vCPU* | 메모리(GiB) | 네트워크 성능(Gbps) |
|---|---|---|---|---|---|
| db.t3.small | 0.052 USD | 1 | 2 | 2 | 최대 5 |
| db.t3.medium | 0.104 USD | 1 | 2 | 4 | 최대 5 |
| db.t3.large | 0.208 USD | 1 | 2 | 8 | 최대 5 |
위의 표는 AWS RDS 서울 리전의 가격과 스펙을 나열한 표입니다.
이번에는 반대로 EC2의 티어는 고정하고 RDS만 스펙을 올려봅시다. 여기서도 가격이 2배씩 증가하는데 DB관련 작업은 2배씩 오를까요?
실제 값
- DB Only : JPA를 활용해 DB 조회를 수행하며, 대부분 DB I/O 작업으로 이루어져 있는 API.
- CPU Only : 복잡한 연산 로직 수행하며, 대부분 CPU 작업으로 이루어져 있는 API.
- ALL : 위의 두 작업을 같이 수행하는 API.
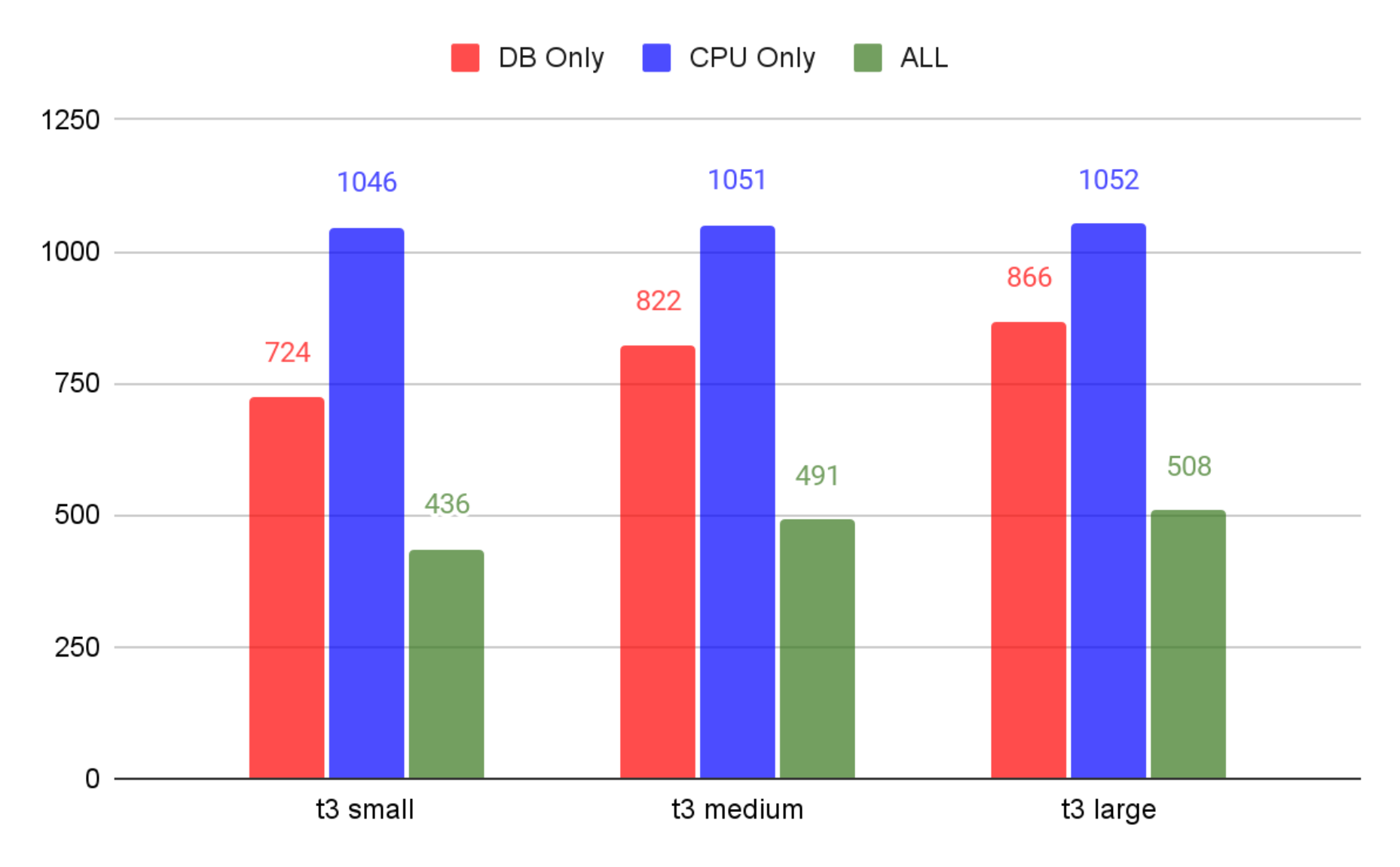
여기서는 아래와 같이 분석할 수 있겠네요.
- DB 관련 작업(DB Only)은 성능이 조금씩 오르긴 하지만 가격에 비하면 미미하다.
3. 왜 그럴까? 리소스 사용량 확인
성능이 조금씩 오르긴 하지만 뭔가 제대로 오른 스펙을 활용하고 있지 않는다는 느낌이 듭니다. 그럼 리소스 사용량을 확인해 볼까요?
아래는 AWS Cloud Watch로 확인한 각 인스턴스의 CPU 사용량 그래프입니다.
EC2 : t3.2xlarge / RDS : db.t3.medium 사용량
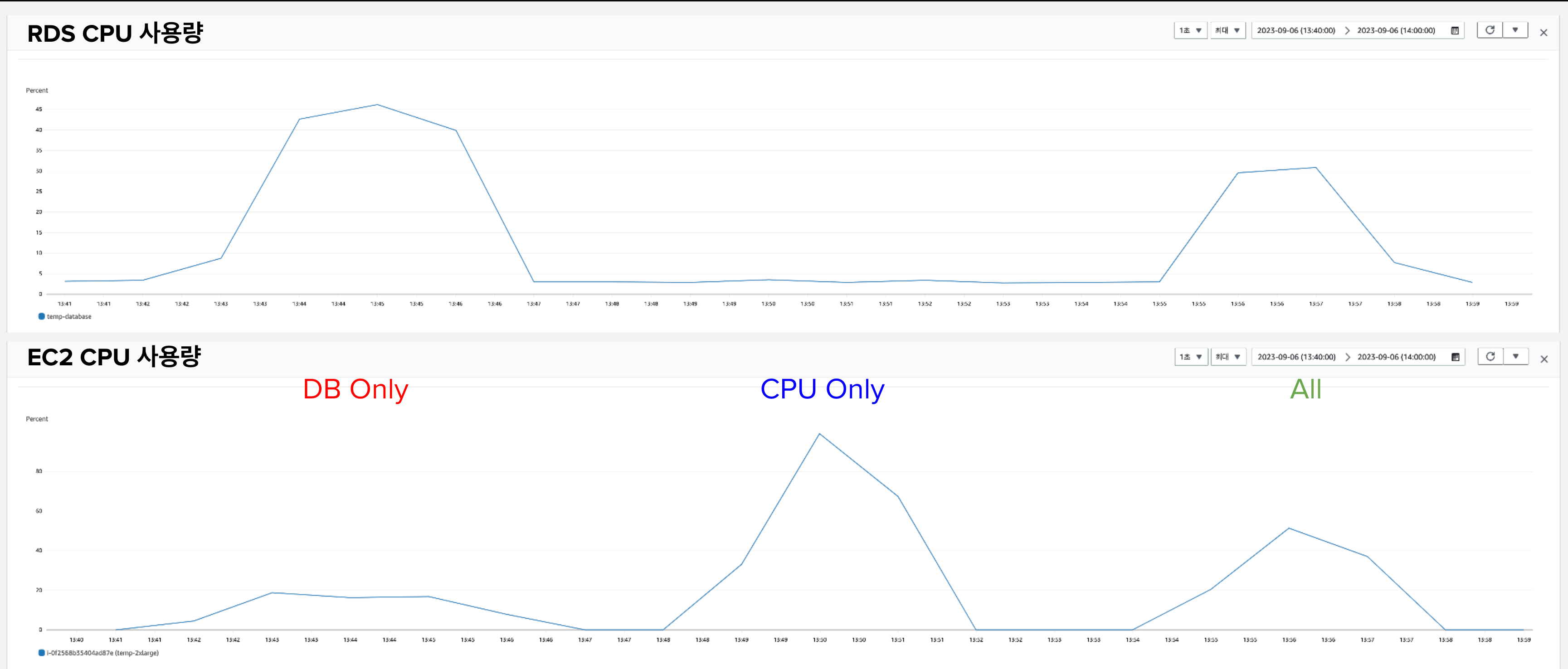
위의 표에서 볼 수 있는 것은 다음과 같습니다.
- DB Only 작업에서 RDS의 성능을 전부 사용하지 않고 있음. (RDS CPU 사용량 약 45%)
- CPU Only 작업에서 EC2의 성능을 전부 사용하고 있음. (EC2 CPU 사용량 약 99%)
“Spring Boot의 기본 설정으로는 EC2의 성능을 전부 활용할 수 있지만, RDS의 성능을 전부 활용하지 않는다.”
4. 원인 분석

해당 글에서 얘기하고자 하는 내용은 Tomcat의 Thread Pool 과 Hikari Connection Pool 입니다.
그리고 먼저 스포하자면 Spring Boot 의 기본 설정은 아래와 같기 때문에 위와 같은 결과가 나온 것입니다.
- Thread Pool 기본 값 : 충분한 스레드 풀을 설정하여 서버의 성능을 최대한 사용할 수 있도록 함.
- Connection Pool 기본 값 : RDS의 성능을 전부 활용하지 못하도록 제한하고 있음.
그럼 Thread Pool, Connection Pool이 뭐길레 성능에 영향을 미칠까요?
들어가기 전 설명: Pool 이란?
컴퓨터 과학에서의 풀은 자원을 사용하는 시점에 메모리에 올리고, 사용을 완료한 이후 메모리에서 해제하는 대신 이미 사용할 준비가 된 자원을 메모리 위에 일정량 미리 생성해둔 자원의 집합이다. 자원이 필요할 경우 새로 자원을 생성하는 대신 풀에서 꺼내 사용하고, 사용이 완료된 경우 자원을 해제하는 대신 풀에 다시 반환하는 형태로 사용한다.
미리 자원을 생성해두면 어떤 이점을 얻게 될까? 자원을 필요할 때 자원의 생성, 파괴 비용을 절약할 수 있다. 즉, 오버헤드(overhead)를 줄일 수 있다. 데이터베이스 혹은 소켓 등은 상대방과 연결하기 위해 꽤 오랜 시간이 걸린다. 미리 커넥션을 생성해두고, 이 커넥션을 재사용하는 방식을 사용하면 애플리케이션의 성능을 개선할 수 있을 것이다.
5-1. 서버 성능 올리기 :: Tomcat Thread Pool
우선, 이전의 측정 값을 보면 다음과 같이 정리할 수 있습니다.
- Spring Boot의 기본 설정으로는 EC2의 CPU 사용량이 99% 까지 올라갔다.
- 즉, 기본 설정은 EC2의 성능을 제한하지 않는 것으로 봐도 무방하다.
- 서버의 코어 수가 증가함에 따라 Cpu와 관련된 작업(Cpu Only, ALL)의 성능이 향상되었다.
-> CPU 작업은 스레드를 통해 이뤄지며, Spring Boot에서는 Tomcat의 Thread Pool을 통해 스레드를 관리한다.
Tomcat Thread Pool 이란?
- 필요한 스레드를 스레드 풀에 보관하고 관리한다.
min-spare ~ max - 스레드 풀에 생성 가능한 스레드의 최대치를 관리한다.
max - 스레드가 필요하면 이미 생성되어있는 스레드를 스레드 풀에서 꺼내 사용한다.
- 사용을 종료하면 스레드 풀에 해당 스레드를 반납한다.
- 최대 스레드가 모두 사용중이어서 스레드 풀에 스레드가 없다면 기다리는 요청은 거절하거나 특정 숫자만큼만 대기하도록 설정할 수 있다.
Default Setting
1
2
3
4
5
6
7
8
server:
tomcat:
threads:
max: 200 # 생성할 수 있는 thread의 총 개수
min-spare: 10 # 항상 활성화 되어있는(idle) thread의 개수
max-connections: 8192 # 수립가능한 connection의 총 개수
accept-count: 100 # 작업큐의 사이즈
connection-timeout: 20000 # timeout 판단 기준 시간, 20초
→ 10개의 스레드를 항상 유지하고, 최대 200개 까지 생성될 수 있다.
즉, 많아봤자 8코어 16코어였던 코어 수에 비해 최대 스레드 수가 충분히 많기(200) 때문에 서버의 CPU 성능을 99% 사용할 수 있었고, 코어 수 만큼 성능이 증가할 수 있었던 것이죠!
Custom Setting
그렇다면 CPU의 최대 사용량을 Thread Pool의 개수를 낮춤으로서 제어할 수 있지 않을까요? 바로 테스트해 봅시다.
- 설정 값 : 최대 스레드 수를 EC2(t3.2xlarge) 8코어의 절반인 4 설정.
- 기대 값 : CPU의 사용량이 약 50프로가 넘지 않고 성능도 그만큼 낮아질 것으로 기대.
1
2
3
4
5
server:
tomcat:
threads:
max: 4
min-spare: 2
성능 비교
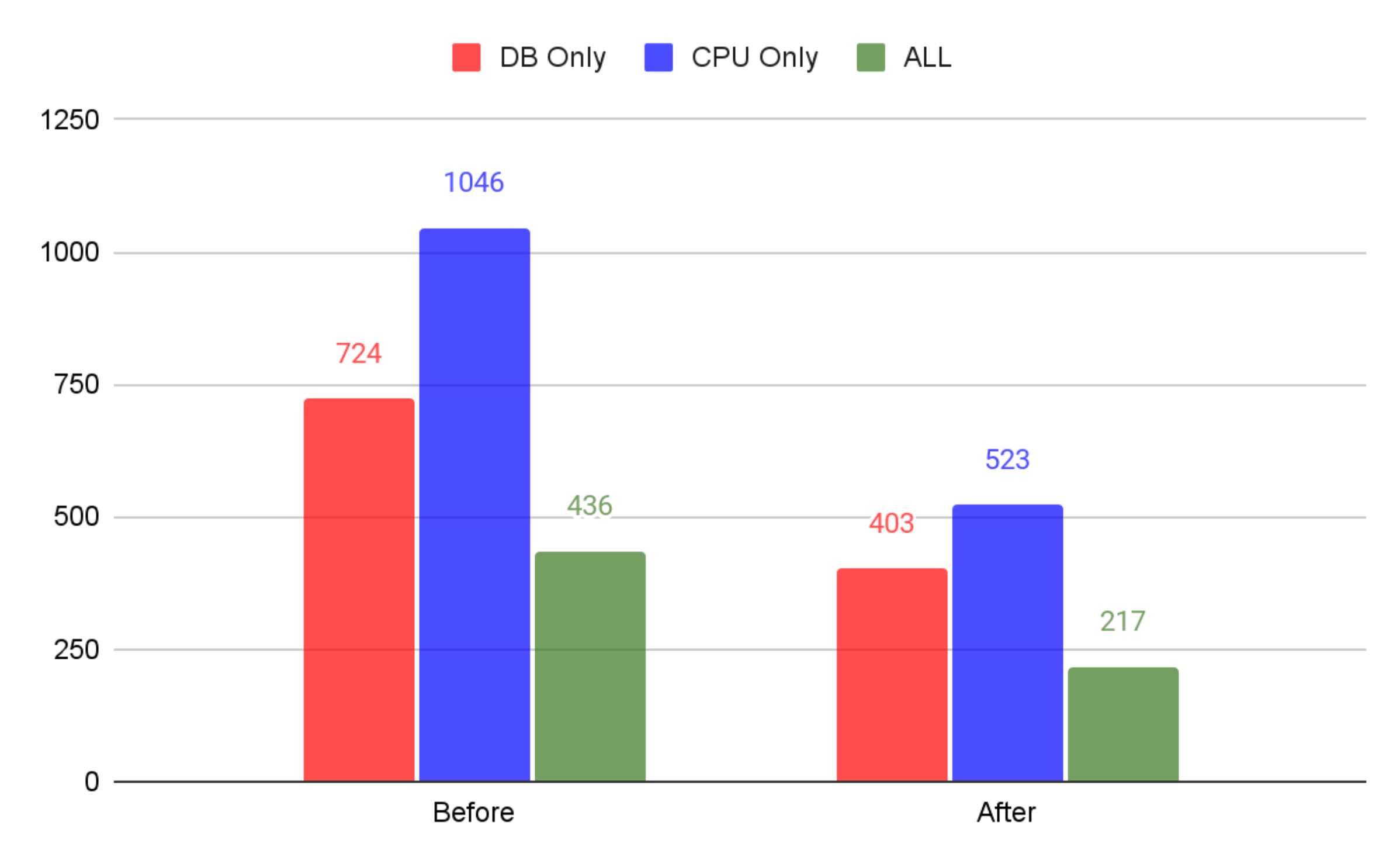
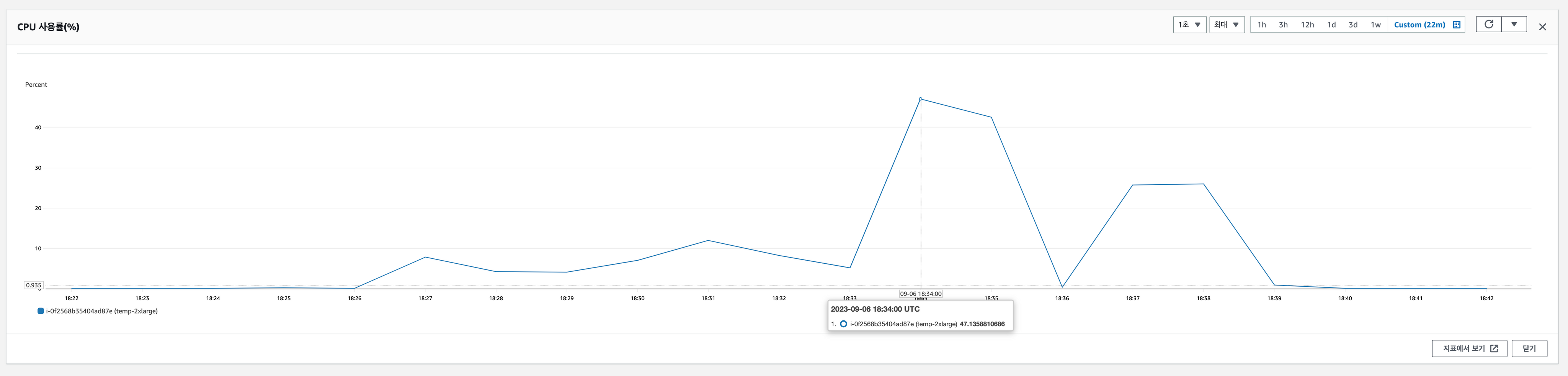
EC2(t3.2xlarge) + RDS(db.t3.medium) 결과.
-> 예상한대로 CPU 사용량과 성능 제한이 정상적으로 이뤄진 걸 볼 수 있습니다. 하지만 CPU 작업 뿐만 아니라 DB 작업도 성능이 저하된 것을 볼 수 있죠.
5-2. 서버 성능 올리기 :: Hikari Connection Pool
RDS의 티어별 성능 측정값을 보면 다음과 같이 정리할 수 있습니다.
- RDS의 티어를 올려도 성능의 증가 폭이 매우 적다.
- 즉, 성능의 제한 값이 존재하는 것으로 유추할 수 있다.
RDS(MySql) Connection 이란?
- DB 연결은 TCP로 이뤄지므로 비용이 많이 든다. → Connection Pool의 필요성
- 따라서 WAS(웹 컨테이너)가 실행될 때 DB연결을 위해 미리 일정수의 connection 객체를 만들어 Pool에 담아 둔다.
- 클라이언트의 요청이 발생하면 Pool에서 생성되어 있는 Connection 객체를 넘겨준다.
- 처리가 끝나면 Connection 객체를 다시 Pool에 보관한다.
Default Setting
1
2
3
4
5
6
7
8
spring:
datasource:
hikari:
maximum-pool-size: 10 # Connection Pool에 유지 가능한 최대 커넥션 개수
minimum-idle: 10 # Connection Pool에 유지 가능한 최소 커넥션 개수
connection-timeout: 30000 # Pool에서 Connection을 구할 때 대기시간
idle-timeout: 600000 # Connection이 Poll에서 유휴상태(사용하지 않는 상태)로 남을 수 있는 최대 시간
max-lifetime: 1800000 # Connection의 최대 유지 가능 시간
→ 항상 10개의 connection을 유지하고 더 늘어나지 않도록 한다.
즉, RDS의 성능이 아무리 좋아도 DB와 통신할 때 사용할 Connection 수가 10개 이상으로 증가하지 않기 때문에 서버의 성능이 오르지 않았던 것입니다.
그럼 이 설정값을 올려주면 성능도 같이 올라갈까요?
Custom Setting
- 우선 사용중인 RDS에서 최대로 지원할 수 있는 Connection 수를 확인해 봅시다. (db.t3.medium)
1
2
3
4
5
6
7
8
-- db.t3.medium 예시
mysql> show variables like 'max_connections';
+-----------------+-------+
| Variable_name | Value |
+-----------------+-------+
| max_connections | 143 |
+-----------------+-------+
1 row in set (0.01 sec)
해당 값보다 크게 설정할 경우 JDBCConnectionException: Unable to acquire JDBC Connection 발생
- 확인한 값을 바탕으로 application.yml 파일에서 hikari cp 설정 변경해 줍시다.
1
2
3
4
5
6
# 간단 예시
spring:
datasource:
hikari:
maximum-pool-size: 130
minimum-idle: 100
성능 비교
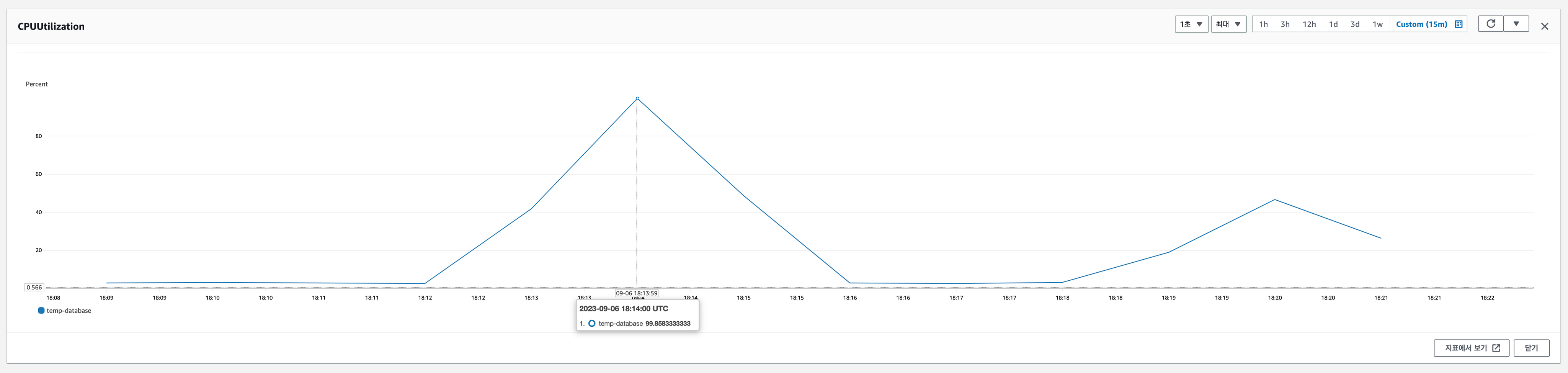
- EC2(t3.2xlarge) + RDS(db.t3.medium) 결과.
- DB 관련 성능(DB Only, ALL)이 크게 증가한 것을 볼 수 있음.
리소스 사용량
 RDS 커넥션 수
RDS 커넥션 수
 RDS CPU 사용량
RDS CPU 사용량
- RDS의 커넥션 수가 설정한 만큼 생성되는 것을 볼 수 있음.
- RDS의 CPU를 거의 최대로 사용하고 있는 것을 볼 수 있음.

Thread Pool과 Connection Pool에 대해 좀 알게 되었으니 이제 같이 적용해 볼까요?!
6. 같이 설정
Custom Setting
- EC2의 8코어를 전부 사용할 수 있도록 Max Thread 수를 8로 설정.
- RDS의 성능을 전부 사용할 수 있도록 Max Connection 수를 130으로 설정.
1
2
3
4
5
6
7
8
9
10
11
server:
tomcat:
threads:
max: 8
min-spare: 4
spring:
datasource:
hikari:
maximum-pool-size: 130
minimum-idle: 100
성능 비교
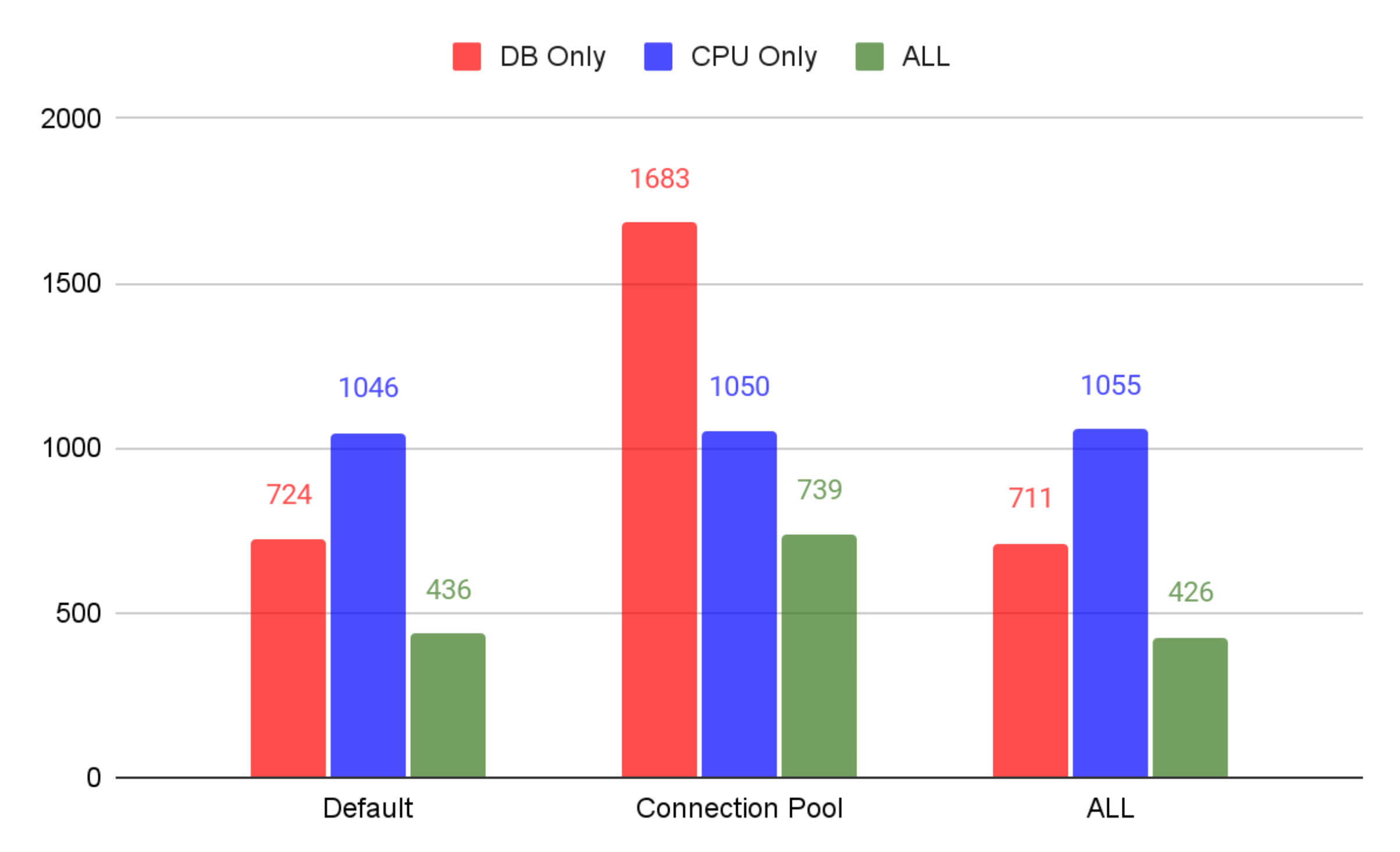
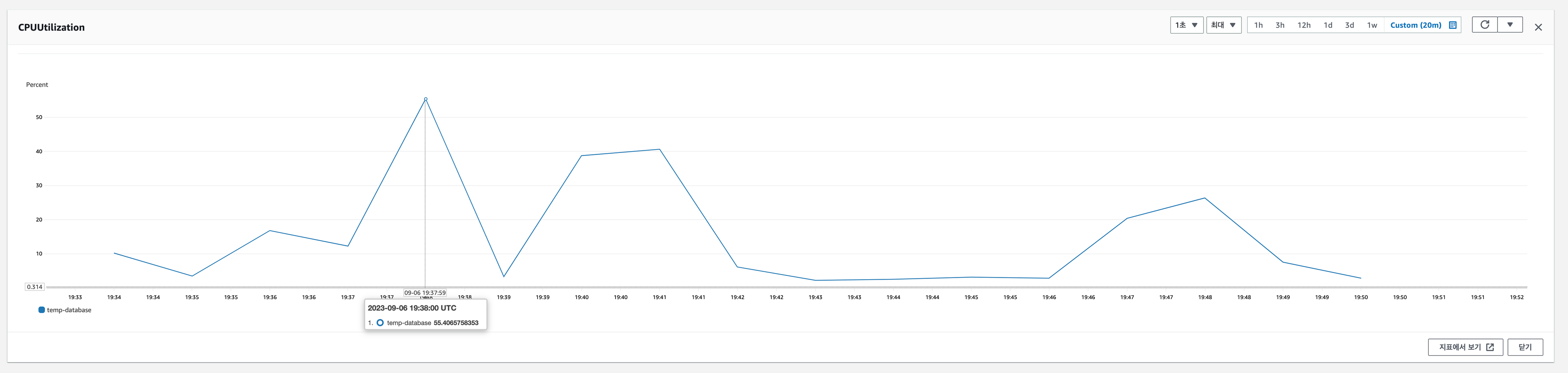 RDS CPU 사용량
RDS CPU 사용량
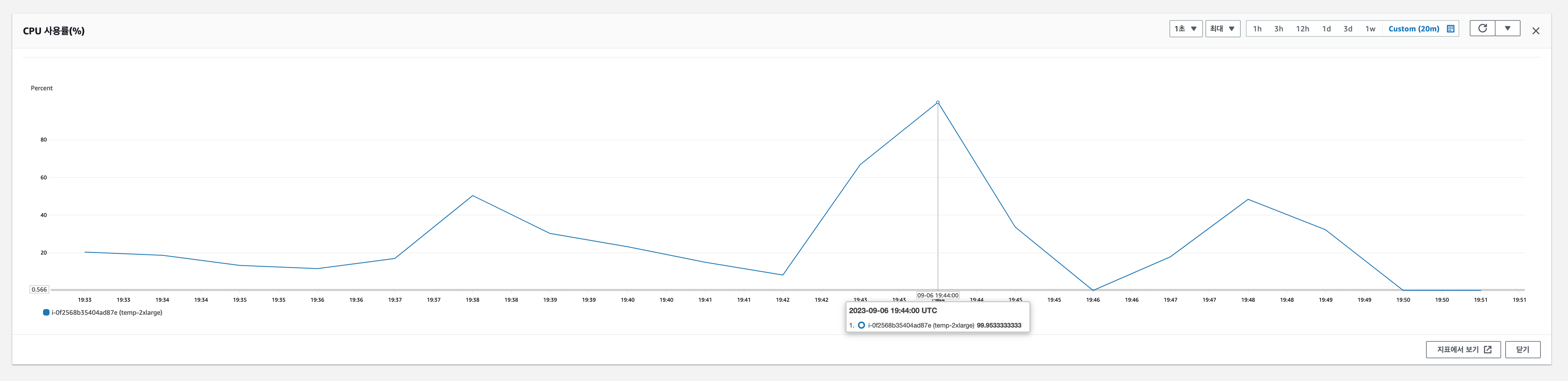 EC2 CPU 사용량
EC2 CPU 사용량
- CPU만 사용하는 작업(CPU Only)의 경우 EC2의 성능은 충분히 사용하고 있음.
- DB와 관련된 작업(DB Only, ALL)의 경우 리소스를 충분히 활용하고 있지 않음.
즉, CPU는 예상했던 대로 성능 향상이 있었지만, DB 관련 성능은 Connnection Pool만 설정했을 때 보다 낮아졌을 뿐만 아니라 기본 설정과 오차 범위 내로 비슷한 수치를 보여주고 있습니다.
왜 그런지는 아래 Spring의 커넥션 관련 로그를 보면 알 수 있는데요.
 Connection Pool 사용량 로그
Connection Pool 사용량 로그
Spring Boot의 로그를 보면 Connection을 8개만 사용하고 있습니다. (= 설정한 스레드 수 만큼 사용)
 흐으음 이건 또 왜 그럴까요..
흐으음 이건 또 왜 그럴까요..
이유 분석
결론부터 말하자면, DB I/O 작업으로 인해 스레드가 쉬게 되는 시간을 고려하지 않았기 때문입니다.
JVM Thread 상태
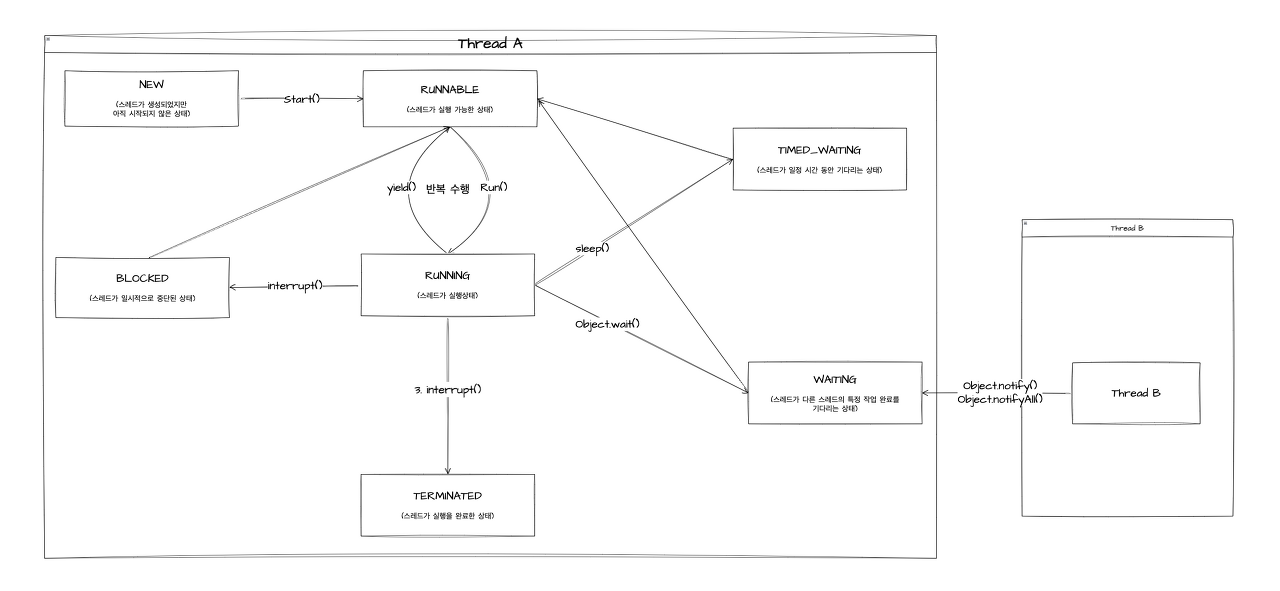
- Thread.State.NEW : 객체 상태스레드가 생성되었지만 아직 시작되지 않은 상태
- Thread.State.RUNNABLE : 실행 대기스레드가 실행 가능한 상태
- Thread.State.BLOCKED : 일시 정지스레드가 일시적으로 중단된 상태
- Thread.State.WAITING : 일시 정지스레드가 다른 스레드의 특정 작업 완료를 기다리는 상태
- Thread.State.TIMED_WAITING : 일시 정지스레드가 일정 시간 동안 기다리는 상태
- Thread.State.TERMINATED : 종료스레드가 실행을 완료한 상태
정리하자면, 스프링이 JPA 메소드를 호출하면 해당 스레드는 블로킹 상태가 됩니다. 그리고 블로킹 상태에서는 스레드 풀에 의해 다른 작업을 수행하도록 해서 CPU를 효율적으로 사용하는 것이죠.
8개의 스레드가 DB 요청을 하고 기다리는 동안 CPU 코어는 다른 스레드 작업을 할 수 있다.
하지만 스레드 풀에 남아있는 스레드가 없기 때문에 기다릴 수 밖에 없게 되었다.
따라서 EC2, RDS 모두 리소스를 전부 활용하지 못하는 상황이 발생하여 성능이 저하된 것이다.
7. 결론
이제 결론을 내봅시다! 그렇다면 적절한 설정 값은 무엇일까요?
적정 Thread Pool
스레드를 많이 생성해둔다고 그 스레드를 다 사용할 수 있는 것은 아닙니다. Default 설정에서 볼 수 있었죠. 그리고 쓸데없이 스레드를 많이 생성한다면 생성하는 데에 드는 자원과 비용이 낭비되기도 하죠.
물론 그렇다고 스레드를 부족하게 만들어둔다면 CPU 사용률이 낮아지게 되고 성능에 제한이 걸리는 상황이 발생합니다.
그래서 적정 스레드 풀을 계산하는 공식이 있습니다.
스레드 풀 적정 크기 = cpu 코어 개수 * (1 / cpu 사용시간 비율)
- I/O 작업 등으로 Thread가 블로킹 되어 있는 시간을 효율적으로 사용하기 위해 나온 공식입니다.
- CPU의 작업이 많다면 코어 수와 가깝게, I/O 작업이 많다면 코어 수 보다 많이 설정하게 됩니다.
스레드 풀 크기는 적정 크기를 정확하게 계산하는 것 보다, 너무 부족하게 세팅하여 cpu가 놀고있거나 너무 과도하게 크게 세팅하여 더 많은 자원(Context Switch)을 불필요하게 사용하지 않게 만드는 것이 더 중요하다고 합니다.
적정 Connection Pool
Connection Pool은 서버 개수와 DB 인스턴스의 성능을 고려해서 결정해야 합니다. 하지만 최소한의 개수는 필요한데 그 공식은 아래와 같습니다.
커넥션 풀 적정 크기 = 전체 Thread 개수 * (하나의 Task에서 동시에 필요한 Connection 수 - 1) + 1
Connection Pool은 우선 Thread Pool 보다는 많이 설정해야 합니다. 데드락에 걸릴 수 있기 때문인데 자세한건 여기에서 볼 수 있습니다. (아래 공식에서 +1이 붙은 이유)
그리고 만약 Thread Pool의 크기보다 Connection Pool의 크기가 훨씬 더 크면 메모리 상에서 남은 Connection은 작업을 하지 못하고 놀게 되기에, 실직적으로 메모리만 차지하게 됩니다.
마치며
적절한 Thread Pool과 Connection Pool을 설정하는건 단순히 공식으로 구하긴 어렵습니다. 기능마다, 환경마다 다르기 때문이죠. 하지만 위에서 볼 수 있듯이 서버 성능에 매우 큰 영향을 미치며 잘못 설정하면 치명적인 오류가 발생하기도 합니다.
결론은 잘 알고 쓰자!