
들어가며
지난 포스트에서 Elastic Stack 로그 모니터링 환경에 대해 알아보았습니다.
하지만… ELK를 구축하는 건 꽤 어렵습니다. 시간도 많이 들고, 서버 리소스도 많이 잡아먹습니다. 시간적으로 보나 경제적으로 보나 비싸다는 얘기죠. 고차원적인 로그 분석이 필요한 게 아니라면 사실 오버엔지니어링이 될 가능성이 있습니다.
그럼 설치가 훨씬 쉽고, 별도의 서버 구축도 필요 없고, 가격까지 착한 서비스가 있다면 어떨까요?
AWS Athena
![]() Image Reference: https://aws.amazon.com/ko/trademark-guidelines/
Image Reference: https://aws.amazon.com/ko/trademark-guidelines/
Amazon Athena는 표준 SQL을 사용해 Amazon S3에 저장된 데이터를 간편하게 분석할 수 있는 대화식 쿼리 서비스입니다. Athena는 서버리스 서비스이므로 관리할 인프라가 없으며 실행한 쿼리에 대해서만 비용을 지불하면 됩니다.
AWS Athena의 가장 중요한 키포인트는 ‘서버리스 서비스‘라는 것입니다. 서버가 따로 돌아가지 않기 때문에 운영 비용이 들지 않고, 조회할 때마다 요금이 발생하는 방식입니다. 심지어 그 금액도 스캔한 데이터의 TB당 5.00 USD(2022년 8월 기준)로 굉장히 저렴합니다. 요금 링크
아래는 AWS에서 설명하는 Athena의 이점입니다. 요약한 내용이며 자세한 내용은 여기를 눌러주세요.
- Start querying instantly
- Athena는 서버리스 서비스입니다. Amazon S3에 저장된 데이터를 지정하고 스키마를 정의한 다음 기본적으로 제공되는 쿼리 편집기를 사용해 쿼리를 시작하면 됩니다.
- Pay per query
- Amazon Athena에서는 실행한 쿼리에 대한 비용만 지불합니다. 데이터를 압축 및 파티셔닝하고 컬럼 형식으로 변환함으로써 쿼리당 비용을 30%에서 90% 절감하고 성능을 더 향상할 수 있습니다.
- Open, powerful, standard
- Amazon Athena는 ANSI SQL을 지원하는 Presto를 사용하며, CSV, JSON 등 다양한 표준 데이터 형식과 호환됩니다. Athena는 대화형 쿼리에 적합하며 대용량 조인, 윈도 함수, 어레이 등 복잡한 분석을 처리하는데도 손색이 없습니다.
- Fast, really fast
- Amazon Athena에서는 빠른 속도의 대화식 쿼리 성능을 구현하기 위해 컴퓨팅 리소스가 충분한지 걱정할 필요가 없습니다. Amazon Athena는 병렬 방식으로 쿼리를 자동 실행하기 때문에 대부분 결과가 수 초 만에 반환됩니다.
그럼 AWS Athena 환경 구축을 직접 해보며 얼마나 간단한지 확인해 봅시다.
Athena 설정하기
해당 포스트에서는 S3 버킷에 ELB의 Access Log가 수집되고 있음을 가정하고 AWS Athena 설정 방법을 설명합니다.
1. IAM 권한 설정
AWS Athena 콘솔을 사용하기 위해서는 추가적인 IAM 권한 설정이 필요합니다. 아래의 두 가지의 정책을 기본으로 하며 별도로 수정도 가능합니다.
자세한 내용은 AWS Athena IAM 공식문서를 참고해 주세요.
AWSQuicksightAthenaAccess
Amazon QuickSight와 Athena의 통합에 필요한 작업에 대한 액세스 권한을 부여
- athena : Athena 리소스에 대한 액세스를 허용.
- glue : AWS Glue 데이터베이스, 테이블 및 파티션에 대한 액세스를 허용.
- s3 : Amazon S3에서 쿼리 결과를 읽고 쓰거나, Amazon S3에 상주하는 공개적으로 사용할 수 있는 Athena 데이터 예제를 읽거나, 버킷을 나열할 수 있도록 허용.
- lakeformation : 보안 주체가 Lake Formation에 등록된 데이터 레이크 위치의 데이터에 액세스하기 위해 임시 자격 증명을 요청하도록 허용.
AmazonAthenaFullAccess
Athena에 대한 완전한 액세스 권한 부여
- sns : Amazon SNS 주제를 나열하고 주제 속성을 가져올 수 있도록 허용. 이를 통해 모니터링 및 알림 목적으로 Athena에 Amazon SNS 주제를 사용할 수 있음.
- cloudwatch : 보안 주체에게 CloudWatch 경보의 생성, 읽기 및 삭제를 허용.
- +AWSQuicksightAthenaAccess 정책 전부
2. S3 설정
Athena의 검색 대상이 될 S3를 지정합니다. 해당 S3의 prefix를 입력하고 저장 버튼을 눌러줍니다.
여기서 Athena와 S3의 리전은 같아야 합니다.
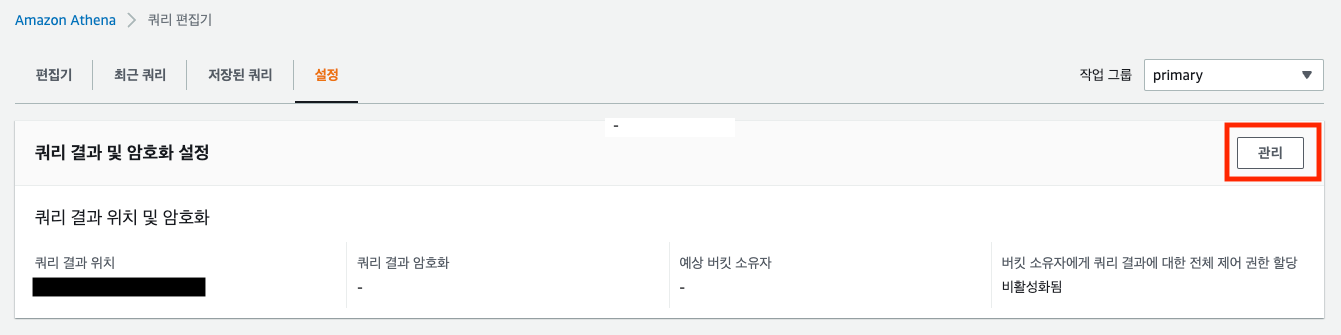
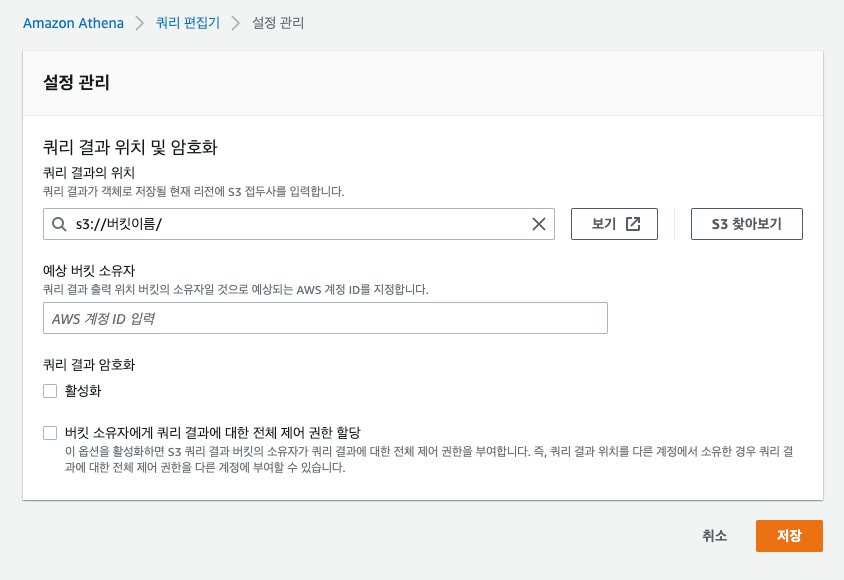
쿼리편집기 → 설정 → 관리 → 쿼리 대상 S3 버킷 저장
3. 데이터베이스, 테이블 생성
편집기에서 아래의 쿼리문을 통해 데이터베이스와 테이블을 생성합니다.
쿼리문 제일 마지막에 있는 location 부분에 S3 환경에 맞추어 수정하고 실행합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
CREATE EXTERNAL TABLE IF NOT EXISTS elb_log (
type string,
time string,
elb string,
client_ip string,
client_port int,
target_ip string,
target_port int,
request_processing_time double,
target_processing_time double,
response_processing_time double,
elb_status_code string,
target_status_code string,
received_bytes bigint,
sent_bytes bigint,
request_verb string,
request_url string,
request_proto string,
user_agent string,
ssl_cipher string,
ssl_protocol string,
target_group_arn string,
trace_id string,
domain_name string,
chosen_cert_arn string,
matched_rule_priority string,
request_creation_time string,
actions_executed string,
redirect_url string,
lambda_error_reason string,
target_port_list string,
target_status_code_list string,
classification string,
classification_reason string
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = '1',
'input.regex' =
'([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*):([0-9]*) ([^ ]*)[:-]([0-9]*) ([-.0-9]*) ([-.0-9]*) ([-.0-9]*) (|[-0-9]*) (-|[-0-9]*) ([-0-9]*) ([-0-9]*) \"([^ ]*) ([^ ]*) (- |[^ ]*)\" \"([^\"]*)\" ([A-Z0-9-]+) ([A-Za-z0-9.-]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^\"]*)\" ([-.0-9]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^ ]*)\" \"([^\s]+?)\" \"([^\s]+)\" \"([^ ]*)\" \"([^ ]*)\"')
LOCATION 's3://<s3 위치>/AWSLogs/<계정 ID>/elasticloadbalancing/<region 위치>/'; -- 설정 필요
4. 데이터 조회
자! 이렇게 AWS Athena 환경 구축이 완료되었습니다.
간단하게 최근 10개 데이터만 조회하는 쿼리문을 실행하여 Athena 환경 구축이 잘 되었는지 확인해 봅시다.
1
2
3
4
5
-- 최근 10개 로그 조회
SELECT *
FROM elb_log
ORDER by time DESC
LIMIT 10;
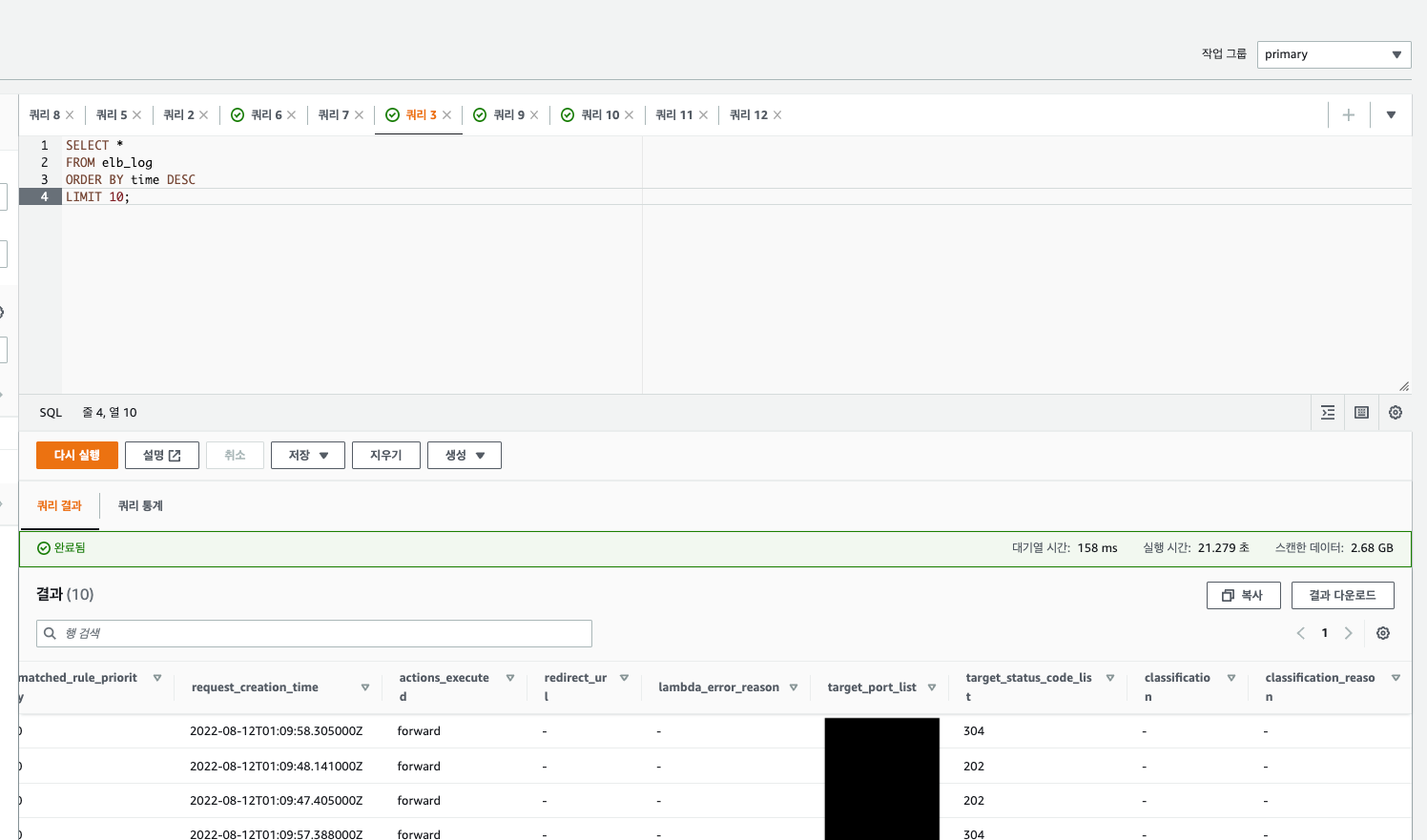
5. 조회 결과
위 사진에서의 제 환경은 약 2년 정도의 로그가 있었습니다. 그리고 사진 우측 아래를 보면 실행시간이 21초나 되고 스캔한 데이터도 2.6GB나 됩니다.
생각보다 성능이 아주아주 안 좋습니다. 겨우 10개의 로그 데이터를 요청한 건데 말이죠.
파티션 프로젝션
위와 같은 결과가 나온 이유는 Athena가 ‘모든 로그데이터’를 스캔하고 그중 10개의 데이터를 반환해서 이러한 현상이 발생한 것입니다.
AWS는 이를 해결하기 위해 파티션을 설정할 수 있도록 하여 스캔해야 하는 데이터의 범위를 줄일 수 있도록 하였습니다.
앞서 말했듯 AWS Athena의 과금 정책은 스캔한 데이터의 양만큼 청구됩니다. 또한 해당 데이터양은 응답 속도에도 영향을 주기 때문에 스캔해야 하는 데이터가 줄이는 것이 필수적입니다. 데이터를 줄임으로써 성능도 올리고 비용도 절감할 수 있는 아주 고마운 친구죠.
그럼 거의 필수라고 할 수 있는 이 파티션 설정을 해봅시다.
1. 테이블 생성
우선 테이블부터 다시 만들어야 합니다. 아래의 쿼리문을 통해 새로 만들어 줍니다.
해당 쿼리문을 통해 테이블을 생성하면 year, month, day 컬럼이 추가되어 데이터가 생성됩니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
CREATE EXTERNAL TABLE IF NOT EXISTS elb_log_partition_projection (
type string,
time string,
elb string,
client_ip string,
client_port int,
target_ip string,
target_port int,
request_processing_time double,
target_processing_time double,
response_processing_time double,
elb_status_code string,
target_status_code string,
received_bytes bigint,
sent_bytes bigint,
request_verb string,
request_url string,
request_proto string,
user_agent string,
ssl_cipher string,
ssl_protocol string,
target_group_arn string,
trace_id string,
domain_name string,
chosen_cert_arn string,
matched_rule_priority string,
request_creation_time string,
actions_executed string,
redirect_url string,
lambda_error_reason string,
target_port_list string,
target_status_code_list string,
classification string,
classification_reason string
)
PARTITIONED BY(year int, month int, day int)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
'serialization.format' = '1',
'input.regex' =
'([^ ]*) ([^ ]*) ([^ ]*) ([^ ]*):([0-9]*) ([^ ]*)[:-]([0-9]*) ([-.0-9]*) ([-.0-9]*) ([-.0-9]*) (|[-0-9]*) (-|[-0-9]*) ([-0-9]*) ([-0-9]*) \"([^ ]*) ([^ ]*) (- |[^ ]*)\" \"([^\"]*)\" ([A-Z0-9-]+) ([A-Za-z0-9.-]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^\"]*)\" ([-.0-9]*) ([^ ]*) \"([^\"]*)\" \"([^\"]*)\" \"([^ ]*)\" \"([^\s]+?)\" \"([^\s]+)\" \"([^ ]*)\" \"([^ ]*)\"')
LOCATION 's3://<s3 위치>/AWSLogs/<계정 ID>/elasticloadbalancing/<region 위치>/';
TBLPROPERTIES (
'has_encrypted_data'='false',
'projection.day.digits'='2',
'projection.day.range'='01,31',
'projection.day.type'='integer',
'projection.enabled'='true',
'projection.month.digits'='2',
'projection.month.range'='01,12',
'projection.month.type'='integer',
'projection.year.digits'='4',
'projection.year.range'='2020,2100',
'projection.year.type'='integer',
"storage.location.template" = "s3://<s3 위치>/AWSLogs/<계정 ID>/elasticloadbalancing/<region 위치>/${year}/${month}/${day}"
);
2. 데이터 조회
아래 쿼리문(예시)으로 특정 날짜에 대한 로그 데이터 10개를 조회해 봅시다.
1
2
3
4
5
-- 2022년 7월 1일 10개 로그 조회
SELECT *
FROM elb_log_partition_projection
WHERE year = 2022 and month = 7 and day = 1
LIMIT 10;
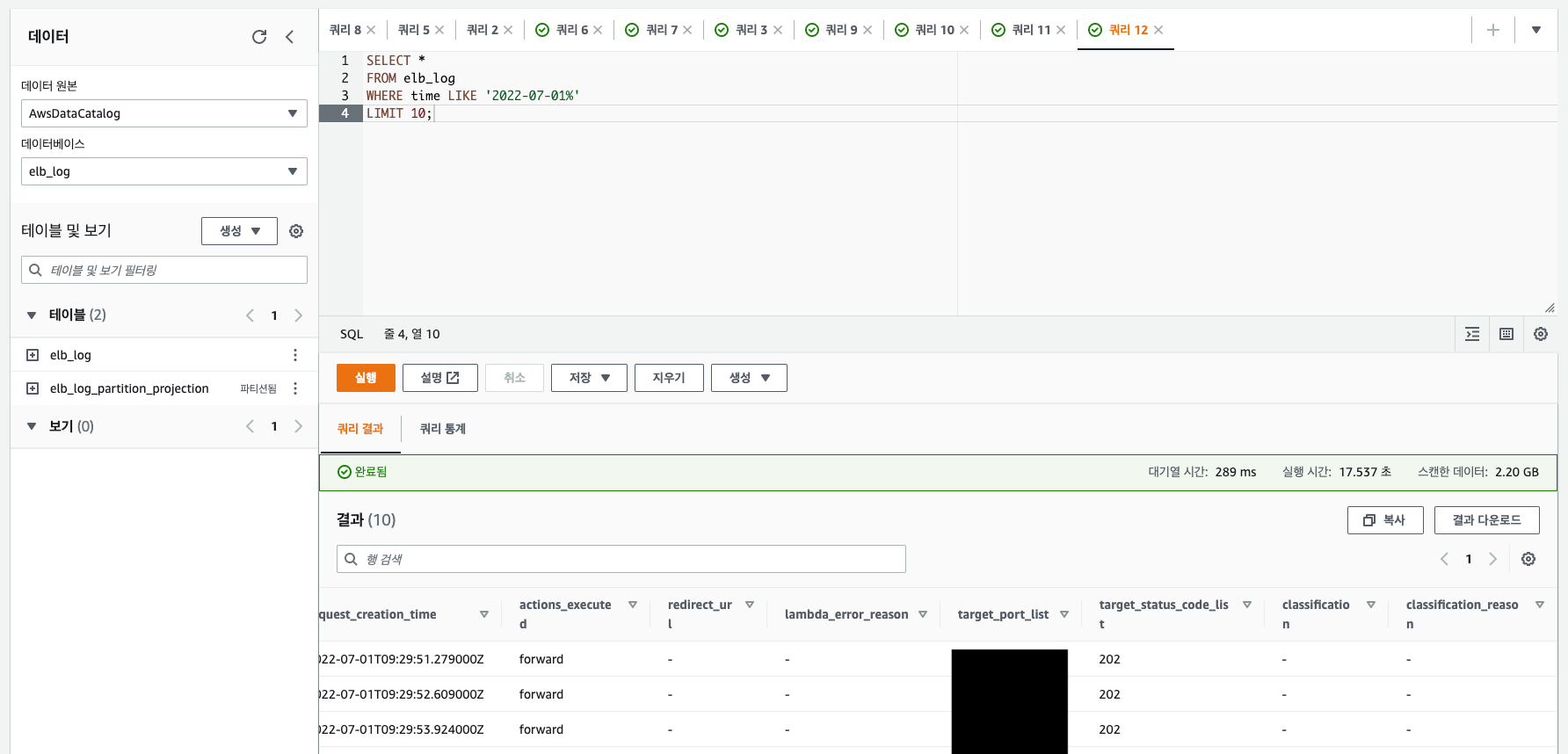
3. 조회 결과
아래의 이미지는 파티션을 설정하지 않은 테이블의 조회 결과입니다. 확실히 파티션을 설정함으로써 쿼리 실행 시간과 스캔한 데이터의 양이 확연히 줄어든 것을 확인할 수 있습니다.
또한 사진 우측에 날짜 정보에 대한 3개의 컬럼이 추가된 것을 볼 수 있습니다. 해당 데이터를 통해 스캔할 데이터의 범위를 줄일 수 있게 된 것이죠.
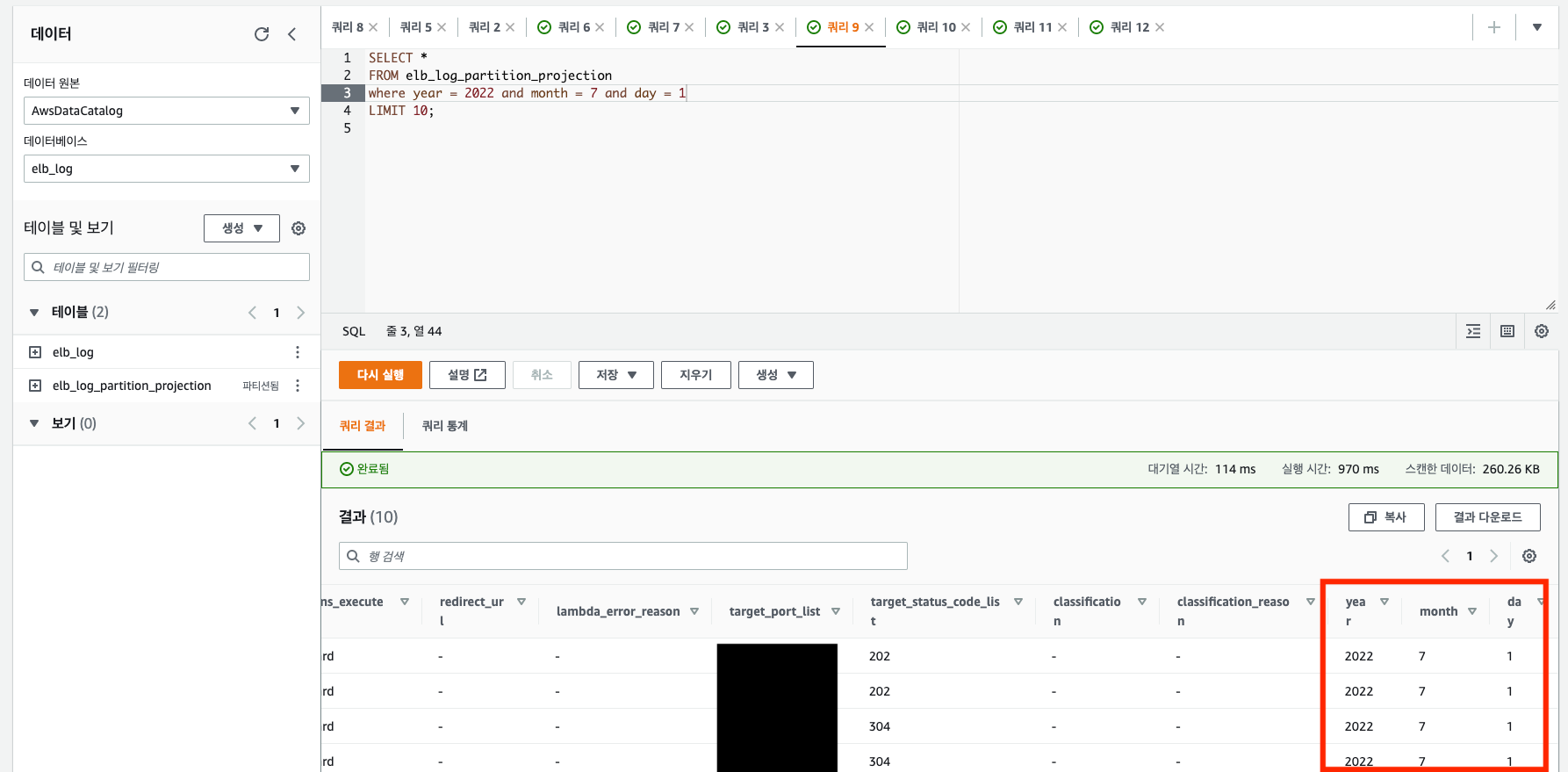
추가로 파티션 프로젝션 설정값을 조정하여 테이블 생성 시 해당 테이블에 포함될 데이터의 조건을 걸어서 전체 데이터가 아닌 조건에 맞는 데이터만 추가되도록 설정할 수 있습니다.
ex) 2020년 로그 테이블 설정 : ‘projection.year.range’=’2020,2020’
마무리하며
AWS Athena 구축은 ELK에 비하면 훠어어얼씬 간단한 편인 것 같습니다. 쿼리문을 통해 검색한다는 점이 누군가에게는 단점이 될 수 있겠지만 사용할 줄만 안다면 큰 장점이 되기도 하고요.
하지만 이름 그대로 AWS에서 제공하는 서비스이기 때문에 AWS에서만 사용이 가능하다는 큰 한계점이 있다는 점과, 모니터링 툴로써는 기능이 거의 없다는 점이 확실한 단점이 될 것 같습니다.
Athena는 간단하게 로그 분석이 필요할 때만 사용하면 좋을 듯합니다. 서버리스 서비스이기 때문에 구축해 놓더라도 운영 요금이 들지 않기 때문에 무지성으로 구축하는 것도 괜찮을 수도…? ㅎㅎ
References
https://aws.amazon.com/ko/premiumsupport/knowledge-center/athena-analyze-access-logs
https://docs.aws.amazon.com/athena/latest/ug/partitions.html
https://jojoldu.tistory.com/537
https://aws.amazon.com/ko/blogs/korea/top-10-performance-tuning-tips-for-amazon-athena/
https://medium.com/bunjang-tech-blog/aws-athena를-사용해서-s3-데이터-조회해보자-bb250f1c2b1f
https://stackoverflow.com/questions/51761067/aws-athena-sql-query-error-with-timestamp